Learn What You Want to Unlearn: Tấn công Đảo ngược Bỏ học
1. Giới thiệu
Trong kỷ nguyên số, dữ liệu cá nhân ngày càng được thu thập và xử lý nhiều hơn bao giờ hết. Đi kèm với đó là những lo ngại về quyền riêng tư và nhu cầu kiểm soát thông tin cá nhân. Các quy định như GDPR ở Châu Âu và CCPA ở California đã ra đời, trao cho người dùng “Quyền được Lãng quên” (Right to be Forgotten) - quyền yêu cầu các tổ chức xóa dữ liệu của họ.
Việc xóa dữ liệu khỏi cơ sở dữ liệu truyền thống tương đối đơn giản. Tuy nhiên, với các mô hình Học máy (Machine Learning), đặc biệt là Mạng Nơ-ron Sâu (Deep Neural Networks - DNNs), việc này phức tạp hơn nhiều do bản chất phức tạp và ngẫu nhiên của quá trình huấn luyện. Để giải quyết thách thức này, kỹ thuật Machine Unlearning (nếu bạn không biết gì về Machine Unlearning thì có thể đọc blog trước tại đây) đã ra đời, nhằm mục đích loại bỏ ảnh hưởng của một số dữ liệu huấn luyện cụ thể khỏi mô hình đã được huấn luyện.
Nghe có vẻ đây là một giải pháp hoàn hảo cho quyền riêng tư? Nhưng liệu quá trình “quên” này có thực sự an toàn? Bài báo “Learn What You Want to Unlearn: Unlearning Inversion Attacks against Machine Unlearning” [Hu et al, 2024] đã thực hiện một nghiên cứu tiên phong, chỉ ra rằng chính quá trình xóa học lại có thể mở ra một bề mặt tấn công mới, làm lộ thông tin nhạy cảm của chính dữ liệu đáng lẽ phải được “quên” đi. Bài viết này sẽ giải mã ý tưởng cốt lõi và các phương pháp tấn công được đề xuất trong nghiên cứu quan trọng này.
2. Mô hình mối đe doạ (Threat Model)
2.1. Bối cảnh và Kẻ tấn công
Để hiểu rõ lỗ hổng mà bài báo khai thác, trước tiên chúng ta cần xác định mô hình đe dọa (threat model), bao gồm bối cảnh hoạt động, mục tiêu của kẻ tấn công, và khả năng của chúng.
Bối cảnh: Cuộc tấn công thường diễn ra trong môi trường Học máy như một Dịch vụ (MLaaS - Machine Learning as a Service). Trong kịch bản này:
- Nhà phát triển mô hình (Model Developer): Huấn luyện mô hình $(M)$ trên dữ liệu riêng tư (bao gồm cả dữ liệu $D_u$ sau này cần xoá) và tải mô hình lên server.
- Nhà cung cấp dịch vụ MLaaS (Server): Triển khai mô hình $M$ và cung cấp API cho người dùng. Khi có yêu cầu xoá dữ liệu $D_u$, nhà phát triển tạo ra mô hình đã unlearn $(M_u)$ bằng một phương pháp unlearning nào đó, rồi tải $M_u$ lên server để thay thế $M$.
- Người dùng cuối (User): Tương tác với mô hình (ban đầu là $M$, sau là $M_u$) thông qua API do server cung cấp.
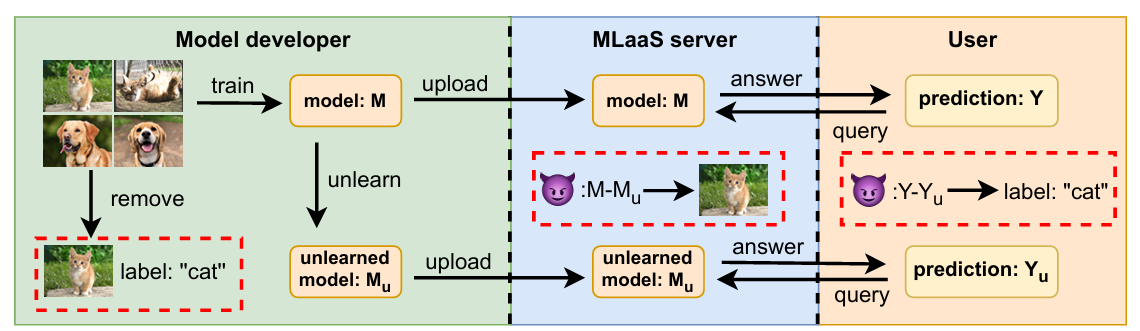
Kẻ tấn công và Khả năng: Bài báo xem xét hai loại kẻ tấn công chính:
- Server MLaaS (Honest-but-Curious):
- Giả định: Server hoạt động đúng chức năng nhưng có thể tò mò và cố gắng trích xuất thông tin từ các mô hình mà nó quản lý.
- Khả năng: Có quyền truy cập White-box vào cả hai mô hình $M$ và $M_u$ (do nhà phát triển tải lên). Nghĩa là server có thể thấy và phân tích các tham số nội bộ $(\theta \text{ và } \theta_u)$
- Hạn chế: Giả định server không biết chính xác thuật toán unlearning nào đã được nhà phát triển sử dụng và cũng không có quyền truy cập vào tập dữ liệu huấn luyện gốc đầy đủ
- Người dùng cuối (Malicious User):
- Giả định: Một người dùng thông thường của dịch vụ MLaaS nhưng có ý đồ xấu.
- Khả năng: Chỉ có quyền truy cập Black-box thông qua API được cung cấp. Người dùng có thể gửi truy vấn đến mô hình và nhận lại kết quả dự đoán. Quan trọng là, người dùng có thể tương tác với mô hình $M$ trước khi nó bị thay thế và tương tác với mô hình $M_u$ sau khi nó được cập nhật.
- Hạn chế: Không thể thấy tham số nội bộ của mô hình
2.2. Mục tiêu Tấn công và Tiêu chí Thành công (Attack Goals and Success Criteria)
Mục tiêu tổng quát của kẻ tấn công là trích xuất thông tin nhạy cảm về dữ liệu đã bị xóa $(D_u)$, làm vô hiệu hóa mục đích bảo vệ quyền riêng tư của việc xóa học. Mục tiêu cụ thể và cách đánh giá thành công phụ thuộc vào loại kẻ tấn công và quyền truy cập của họ:
- Đối với Kẻ tấn công White-box (Server):
- Mục tiêu: Khôi phục Đặc trưng - Feature Recovery. Cố gắng tái tạo lại một mẫu dữ liệu $x’$ sao cho nó càng giống với mẫu dữ liệu gốc đã bị xoá $x^\ast$ càng tốt về mặt hình ảnh hoặc cấu trúc.
- Tiêu chí thành công:
- Đạt điểm cao trên các chỉ số như MSE, LPIPS thấp, PSNR cao
- Quan trọng hơn, tạo ra được $x’$ mà con người có thể nhận dạng được đối tượng hoặc thông tin nhạy cảm chứa trong $x^\ast$ ban đầu, ngay cả khi $x’$ có nhiễu hoặc không hoàn hảo.
- Đối với Kẻ tấn công Black-box (User):
- Mục tiêu: Suy luận Nhãn (Label Inference). Xác định chính xác các label (class) $C_u$ của dữ liệu đã bị xoá khỏi mô hình.
- Tiêu chí thành công:
- Các label được suy luận ra phải trùng khớp với các label thực tế của dữ liệu $D_u$ đã bị xoá.
- Thành công của cuộc tấn công được đo bằng độ chính xác (accuracy) của việc suy luận nhãn.
2.3. Lỗ hổng cốt lõi
Điểm yếu cơ bản nằm ở chỗ kẻ tấn công (dù là server hay người dùng) có khả năng tiếp cận và so sánh trạng thái hoặc hành vi của mô hình trước $(M)$ và sau $(M_u)$ khi quá trình unlearning diễn ra. Chính sự khác biệt phát sinh từ việc loại bỏ dữ liệu $D_u$ là bề mặt tấn công, cho phép kẻ tấn công cô lập và suy luận thông tin về dữ liệu đã bị xoá.
3. Phương pháp Tấn công: Unlearning Inversion Attacks
Bài báo giới thiệu Unlearning Inversion Attacks như một phương pháp mới để chứng minh và khai thác lỗ hổng bảo mật trong quá trình unlearning. Ý tưởng trung tâm là tận dụng thông tin có được từ việc so sánh hai phiên bản mô hình: mô hình gốc $M$ (với tham số $\theta$) và mô hình đã xoá học $M_u$ (với tham số $\theta_u$). Sự khác biệt giữa chúng ẩn chứa “dấu vết” của dữ liệu đã bị xoá $(D_u)$. Phương pháp tấn công được chia thành hai kịch bản chính, tuỳ thuộc vào quyền truy cập của kẻ tấn công:
3.1. Khôi phục Đặc trưng (Feature Recovery - White-box)
Kịch bản này giả định kẻ tấn công là Server MLaaS (hoặc bất kỳ ai có quyền truy cập white-box), nghĩa là họ có thể xem và thao tác trực tiếp trên các tham số $\theta$ và $\theta_u$ của cả hai mô hình. Mục tiêu là tái tạo lại đặc trưng (ví dụ: hình ảnh) của một mẫu dữ liệu $x^\ast \in D_u$ đã bị xoá. Quá trình gồm hai bước chính:
-
Bước 1: Ước lượng Gradient của Dữ liệu đã xoá $(\nabla^\ast)$
-
Ý tưởng: Trong quá trình huấn luyện ML thông thường, tham số mô hình được cập nhật dựa trên gradient của hàm mất mát tính trên dữ liệu huấn luyện. Công thức cập nhật cơ bản (như Stochastic Gradient Descent - SGD - Eq. 1 trong paper) là:
\[\theta_{k+1} = \theta_k - \alpha \nabla_\theta \mathcal{L} (\theta_k)\]Trong đó $\theta_k$ là tham số ở bước $k$, $\alpha$ là tốc độ học, và $\nabla_\theta \mathcal{L} (\theta_k)$ là gradient của hàm mất mát $\mathcal{L}$ tính trên một batch dữ liệu. Điều này có nghĩa là sự thay đổi tham số $(\theta_{k+1} - \theta_k)$ xấp xỉ với thông tin gradient (âm) của batch dữ liệu đó.
-
Áp dụng vào Unlearning: Tương tự, sự khác biệt giữa mô hình gốc $\theta$ (đã “học” $D_u$) và mô hình đã unlearn $\theta_u$ (đã “quên” $D_u$) phải chứa thông tin gradient liên quan đến $D_u$. Kẻ tấn công ước lượng thông tin gradient này bằng cách tính hiệu đơn giản (Eq. 2 trong paper):
\[\nabla^\ast = \theta - \theta_u\] -
Lưu ý: $\nabla^\ast$ chỉ là một ước lượng cho thông tin gradient của $D_u$. Nó không phải là một gradient chính xác vì kẻ tấn công không biết chi tiết về thuật toán xóa học cụ thể mà nhà phát triển đã sử dụng.
-
-
Bước 2: Đảo ngược Gradient Ước lượng (Gradient Inversion)
-
Thách thức: Làm thế nào để khôi phục lại dữ liệu gốc $x^\ast$ từ gradient ước lượng $\nabla^\ast$?
-
Giải pháp: Lấy cảm hứng từ các kỹ thuật tấn công đảo ngược gradient trong Học liên kết (Federated Learning).
-
Điều chỉnh cho Unlearning: Do chỉ có gradient ước lượng ($\nabla^\ast$), bài báo sử dụng phương pháp tối ưu hóa tập trung vào việc khớp hướng của gradient.
-
Quy trình tối ưu hóa:
- Khởi tạo một dữ liệu giả lập (dummy input) $x’$ và nhãn giả lập (dummy label) $y’$.
-
Tính gradient $\nabla’$ của hàm mất mát $\mathcal{L}$ đối với tham số $\theta$ của mô hình gốc M dựa trên $x’$ và $y’$ (Eq. 3 trong paper):
\[\nabla' = \frac{\partial \mathcal{L} (f_\theta (x'), y')}{\partial \theta}\] -
Tìm $x’$ tối ưu bằng cách giải bài toán tối ưu sau (Eq. 4 trong paper):
\[\arg\min_{x'} -l(\nabla', \nabla^\ast) + \alpha TV(x')\]trong đó:
-
$l(\nabla’, \nabla^\ast)$ là độ tương tự cosine (cosine similarity) giữa $\nabla’$ và $\nabla^\ast$ (Eq. 5 trong paper):
\[l(\nabla', \nabla^\ast) = \frac{\langle \nabla', \nabla^\ast \rangle}{\| \nabla' \|_2 \| \nabla^\ast \|_2}\](Việc tối ưu để cực đại hóa độ tương tự cosine - tương đương cực tiểu hóa $-l$ - giúp đảm bảo $\nabla’$ và $\nabla^\ast$ có cùng hướng).
-
$TV(x’)$ là hàm Tổng biến thiên (Total Variation), một hàm chính quy hóa (regularizer) (Eq. 6 trong paper):
\[TV(x') = \sum_{i, j \in N} \|c_i - c_j\|_1\]($N$ là các cặp pixel hàng xóm, $c_i, c_j$ là giá trị pixel. Giúp ảnh $x’$ tái tạo mượt mà hơn).
-
$\alpha$ là một siêu tham số cân bằng.
-
-
Kết quả: Quá trình tối ưu hóa sẽ tìm ra $x’$ mà khi đưa qua mô hình gốc $M$ sẽ tạo ra gradient $\nabla’$ có hướng gần nhất với $\nabla^\ast$. $x’$ này chính là đặc trưng được khôi phục của dữ liệu đã xóa $x^\ast$.
-
Ví dụ minh họa (Feature Recovery):
Giả sử nhà phát triển đã xóa một ảnh con mèo ($x^\ast$) khỏi mô hình $M$ để tạo ra mô hình $M_u$. Server MLaaS (kẻ tấn công) không có ảnh gốc $x^\ast$ nhưng có $\theta$ và $\theta_u$.
- Server tính $\nabla^\ast = \theta - \theta_u$. Vector $\nabla^\ast$ này giờ chứa thông tin gradient ước lượng liên quan đến ảnh con mèo đã bị xóa.
- Server khởi tạo một ảnh nhiễu ngẫu nhiên $x’$ và giả sử nhãn là “mèo” ($y’=3$). Server dùng mô hình gốc $M$ để tính gradient $\nabla’$ cho cặp $(x’, y’=3)$.
- Server chạy thuật toán tối ưu hóa (Eq. 4) để điều chỉnh ảnh $x’$. Mục tiêu là làm cho gradient $\nabla’$ (tính từ $x’$ hiện tại) ngày càng giống với $\nabla^\ast$ về mặt hướng (cosine similarity cao), đồng thời giữ cho $x’$ không quá nhiễu (nhờ TV).
- Kết quả: Sau khi tối ưu, ảnh $x’$ sẽ trông giống ảnh con mèo $x^\ast$ ban đầu đã bị xóa, mặc dù có thể hơi mờ hoặc có nhiễu. Server đã khôi phục được đặc trưng của dữ liệu bị xóa.
3.2. Suy luận Nhãn (Label Inference - Black-box)
Kịch bản này giả định kẻ tấn công là Người dùng cuối (End-user) với quyền truy cập black-box thông qua API. Mục tiêu là xác định (các) nhãn $C_u$ của dữ liệu $D_u$ đã bị xóa.
Cách thức:
-
Bước 1: Tạo các Mẫu thăm dò (Probing Samples)
-
Ý tưởng: Khai thác sự thay đổi trong hành vi dự đoán (cụ thể là độ tin cậy) của mô hình trước và sau khi xóa học.
-
Quy trình:
- Chuẩn bị một tập dữ liệu nhỏ $D_p$.
- Với mỗi lớp $y_t$ (ví dụ: 0 đến 9 cho CIFAR-10), tối ưu hóa một số mẫu (ví dụ: $m=10$) từ $D_p$ thành $x’$ sao cho mô hình gốc M dự đoán $x’$ thuộc lớp $y_t$ với độ tin cậy cực cao.
-
Sử dụng kỹ thuật tấn công black-box như ZOO. Mục tiêu là cực tiểu hóa hàm (Eq. 8 trong paper):
\[g(x', y_t) = \max_{i \neq y_t} [Z(x')]_i - [Z(x')]_{y_t}\](Trong đó $Z(x’)$ là vector logits của mô hình gốc M).
- Lưu các mẫu thăm dò $x’$ đã tối ưu hóa cho từng lớp $y_t$ và vector dự đoán $\hat{\mathcal{Y}}$ (kết quả từ mô hình gốc M) tương ứng vào bộ dữ liệu thăm dò $D_p$.
-
-
Bước 2: Thăm dò Mô hình Đã xóa học $(M_u)$
-
Kẻ tấn công dùng toàn bộ bộ dữ liệu thăm dò $D_p$ (chứa các mẫu $x’$ đã tối ưu cho tất cả các lớp) để truy vấn mô hình $M_u$.
-
Với mỗi mẫu thăm dò $x’_i \in D_p$, ghi lại vector dự đoán $\mathcal{Y}_i$ từ mô hình $M_u$.
-
-
Bước 3: Tính toán Độ thay đổi Tin cậy và Suy luận Nhãn
-
Ý tưởng: Nếu lớp $C_{unlearn}$ bị xóa, mô hình $M_u$ sẽ kém tin cậy hơn khi dự đoán các mẫu liên quan đến lớp đó.
-
Tính toán: Với mỗi lớp mục tiêu $y_t$ (lớp mà các mẫu thăm dò $x’_i$ được thiết kế để nhắm tới), tính vector chênh lệch trung bình giữa dự đoán của M và $M_u$ (Eq. 9 trong paper):
\[\Delta_p = \frac{1}{m} \sum_{i=1}^m (\hat{\mathcal{Y}}_i - \mathcal{Y}_i)\]Trích xuất giá trị chênh lệch tại chỉ số tương ứng với lớp $y_t$ (Eq. 10 trong paper):
\[\beta_{y_t} = \Delta_p[y_t]\](Giá trị $\beta_{y_t}$ thể hiện mức độ thay đổi tin cậy trung bình cho lớp $y_t$ sau khi xóa học, được đo trên các mẫu thăm dò được thiết kế cho lớp $y_t$).
-
Suy luận: Tìm lớp $y_t$ có giá trị $\beta_{y_t}$ âm nhất (độ tin cậy giảm nhiều nhất). Lớp này được suy luận là nhãn $C_u$. Công thức trong bài báo là (Eq. 11):
\[C_u = \arg \max_{y_t} (-\beta_{y_t})\] -
Trường hợp nhiều lớp: Chọn ra K lớp có giá trị $\beta_{y_t}$ âm nhất (Top-K).
-
Ví dụ minh họa (Label Inference):
Vẫn giả sử một ảnh con mèo ($x^\ast$, nhãn $y^\ast=3$) đã bị xóa khỏi $M$ để tạo ra $M_u$. Người dùng cuối (kẻ tấn công) không biết dữ liệu nào bị xóa.
- Tạo mẫu thăm dò: Kẻ tấn công tạo các mẫu $x_{airplane}’$, $x_{car}’$, $x_{bird}’$, $x_{cat}’$, $x_{deer}’$, … , $x_{truck}’$ sao cho mô hình gốc $M$ dự đoán chúng thuộc lớp tương ứng (0, 1, 2, 3, 4,…, 9) với độ tin cậy >99.9%. Họ lưu các mẫu này và kết quả $\hat{\mathcal{Y}}$ từ M.
- Thăm dò $M_u$: Sau khi Mu được triển khai, kẻ tấn công gửi tất cả các mẫu thăm dò ($x_{airplane}’, …, x_{truck}’$) đến $M_u$ và nhận về các kết quả dự đoán mới $\mathcal{Y}$.
- Tính toán & Suy luận:
- Kẻ tấn công tính $\beta_{airplane} = \Delta_p[0]$ (sự thay đổi tin cậy cho lớp “airplane” khi dùng mẫu thăm dò “airplane”).
- Tính $\beta_{car} = \Delta_p[1]$ (sự thay đổi tin cậy cho lớp “car” khi dùng mẫu thăm dò “car”).
- …
- Tính $\beta_{cat} = \Delta_p[3]$ (sự thay đổi tin cậy cho lớp “cat” khi dùng mẫu thăm dò “cat”).
- …
- Tính $\beta_{truck} = \Delta_p[9]$ (sự thay đổi tin cậy cho lớp “truck” khi dùng mẫu thăm dò “truck”).
- So sánh: Kẻ tấn công nhận thấy $\beta_{cat}$ có giá trị âm lớn nhất (ví dụ: -0.0008) so với các giá trị $\beta$ khác (thường gần 0 hoặc ít âm hơn).
- Kết luận: Kẻ tấn công suy luận rằng lớp có độ tin cậy giảm nhiều nhất chính là lớp đã bị xóa dữ liệu. Do đó, họ kết luận $C_u = 3$ (lớp “cat”). Họ đã thành công suy luận ra nhãn của dữ liệu bị xóa mà không cần biết dữ liệu đó trông như thế nào.
4. Kết quả thực nghiệm của bài báo
5. Hậu quả và cách Phòng thủ
6. Kết luận
Tài liệu tham khảo
-
K. P., M. S., Nicolazzo, S., Nocera, A., & P, V. (2025). “How Secure is Forgetting? Linking Machine Unlearning to Machine Learning Attacks.” arXiv preprint arXiv:2503.20257. https://arxiv.org/abs/2503.20257
-
Xu, J., Wu, Z., Wang, C., & Jia, X. (2024). “Machine Unlearning: Solutions and Challenges.” IEEE Transactions on Emerging Topics in Computational Intelligence*, 8(3), 2150–2168. DOI: 10.1109/TETCI.2024.3379240
-
Unlearning Challenge (NeurIPS 2023). “Starting Kit: Machine Unlearning on CIFAR-10.” Google Colab Notebook
-
Wang, W., Tian, Z., Zhang, C., & Yu, S. (2024). “Machine Unlearning: A Comprehensive Survey.” arXiv preprint arXiv:2405.07406. https://arxiv.org/abs/2405.07406
-
Hu, H., Wang, S., Dong, T., & Xue, M. (2024). “Learn What You Want to Unlearn: Unlearning Inversion Attacks against Machine Unlearning.” arXiv preprint arXiv:2404.03233. https://arxiv.org/abs/2404.03233
-
Graves, L., Nagisetty, V., & Ganesh, V. (2020). “Amnesiac Machine Learning.” arXiv preprint arXiv:2010.10981. https://arxiv.org/abs/2010.10981
-
Gao, K., Zhu, T., Ye, D., & Zhou, W. (2024). Defending against gradient inversion attacks in federated learning via statistical machine unlearning. Knowledge-Based Systems, 299, 111983. https://doi.org/10.1016/j.knosys.2024.111983